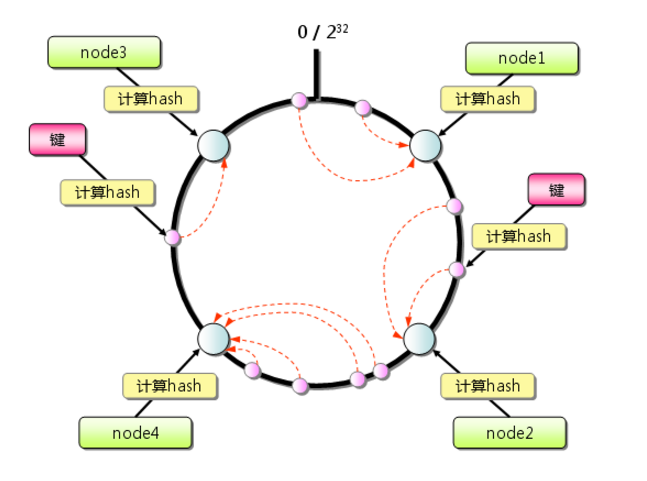
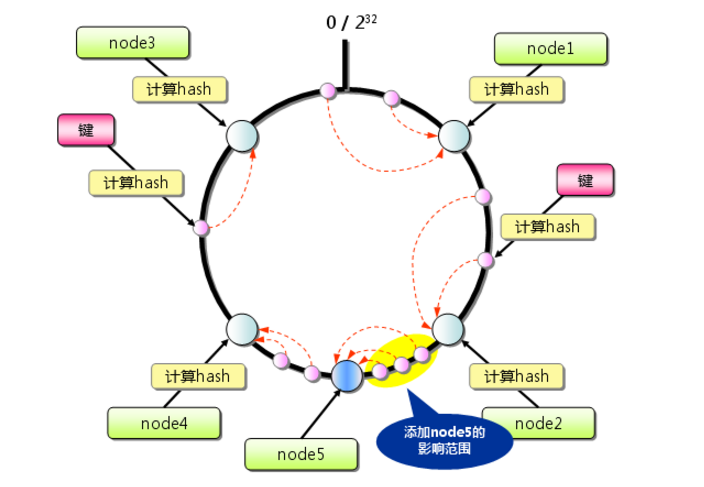
本文在阅读大话数据结构这本书的基础上,结合java语言的特点,来理解查找。
查找(Searching)是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。
顺序表查找
顺序查找又叫线性查找,是最基本的查找技术,它的查找过程是:从表中第一个(或最后一个)记录开始,逐个记性记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所查的记录,查找不成功。
1 | /** |
有序表查找
折半查找
折半查找又称二分查找。它的前提是线性表中的记录必须是关键码有序(通常是从小到大有序),线性表必须采用顺序存储。
折半查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败为止。 时间复杂度为O(logn)
1 | /** |