Unsafe类存在sun.misc.Unsafe中可以直接读写内存、获得地址偏移值、锁定或释放线程。concurrentHashmap的1.7版本大量使用该类来提高提升Java运行效率。下面介绍一下其使用。
基本类信息
1 | public class Dog { |
操作成员变量
1 | public class Test { |
操作数组
1 | public class Test1 { |
Unsafe类存在sun.misc.Unsafe中可以直接读写内存、获得地址偏移值、锁定或释放线程。concurrentHashmap的1.7版本大量使用该类来提高提升Java运行效率。下面介绍一下其使用。
1 | public class Dog { |
1 | public class Test { |
1 | public class Test1 { |
IO的方式通常分为几种,同步阻塞的BIO、同步非阻塞的NIO、异步非阻塞的AIO。
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个”调用“时,在没有得到结果之前,该”调用“就不返回。但是一旦调用返回,就得到返回值了。
换句话说,就是由”调用者“主动等待这个”调用“的结果。
而异步则是相反,调用者在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,”调用者“不会立刻得到结果。而是在”调用“发出后,”被调用者“通过状态、通知来通知”调用者“,或通过回调函数处理这个调用。
典型的异步编程模型比如Node.js
举个通俗的例子:
你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。
而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,
你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,需要先在服务端启动一个ServerSocket,然后在客户端启动Socket来对服务端进行通信,默认情况下服务端需要对每个请求建立一堆线程等待请求,而客户端发送请求后,先咨询服务端是否有线程相应,如果没有则会一直等待或者遭到拒绝请求,如果有的话,客户端会线程会等待请求结束后才继续执行。
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。 也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。
BIO与NIO一个比较重要的不同,是我们使用BIO的时候往往会引入多线程,每个连接一个单独的线程;而NIO则是使用单线程或者只使用少量的多线程,每个连接共用一个线程。

随着大型网站的各种高并发访问、海量数据处理等场景越来越多,如何实现网站的高可用、易伸缩、可扩展、安全等目标就显得越来越重要。为了解决这样一系列问题,大型网站的架构也在不断发展。提高大型网站的高可用架构,不得不提的就是分布式。本文将简单介绍如何有效的解决分布式的一致性问题,其中包括什么是分布式事务,二阶段提交和三阶段提交。
在分布式系统中,为了保证数据的高可用,通常将数据保留多个副本(replica),这些副本会放置在不同的物理的机器上。为了对用户提供正确的增\删\改\差等语义,我们需要保证这些放置在不同物理机器上的副本是一致的。
为了解决这种分布式一致性问题,前人在性能和数据一致性的反反复复权衡过程中总结了许多典型的协议和算法。其中比较著名的有二阶提交协议(Two Phase Commitment Protocol)、三阶提交协议(Three Phase Commitment Protocol)和Paxos算法。
分布式事务是指会涉及到操作多个数据库的事务。其实就是将对同一库事务的概念扩大到了对多个库的事务。目的是为了保证分布式系统中的数据一致性。分布式事务处理的关键是必须有一种方法可以知道事务在任何地方所做的所有动作,提交或回滚事务的决定必须产生统一的结果(全部提交或全部回滚)
在分布式系统中,各个节点之间在物理上相互独立,通过网络进行沟通和协调。由于存在事务机制,可以保证每个独立节点上的数据操作可以满足ACID。但是,相互独立的节点之间无法准确的知道其他节点中的事务执行情况。所以从理论上讲,两台机器理论上无法达到一致的状态。如果想让分布式部署的多台机器中的数据保持一致性,那么就要保证在所有节点的数据写操作,要不全部都执行,要么全部的都不执行。但是,一台机器在执行本地事务的时候无法知道其他机器中的本地事务的执行结果。所以他也就不知道本次事务到底应该commit还是 roolback。所以,常规的解决办法就是引入一个“协调者”的组件来统一调度所有分布式节点的执行。
X/Open 组织(即现在的 Open Group )定义了分布式事务处理模型。 X/Open DTP 模型( 1994 )包括应用程序( AP )、事务管理器( TM )、资源管理器( RM )、通信资源管理器( CRM )四部分。一般,常见的事务管理器( TM )是交易中间件,常见的资源管理器( RM )是数据库,常见的通信资源管理器( CRM )是消息中间件。 通常把一个数据库内部的事务处理,如对多个表的操作,作为本地事务看待。数据库的事务处理对象是本地事务,而分布式事务处理的对象是全局事务。 所谓全局事务,是指分布式事务处理环境中,多个数据库可能需要共同完成一个工作,这个工作即是一个全局事务,例如,一个事务中可能更新几个不同的数据库。对数据库的操作发生在系统的各处但必须全部被提交或回滚。此时一个数据库对自己内部所做操作的提交不仅依赖本身操作是否成功,还要依赖与全局事务相关的其它数据库的操作是否成功,如果任一数据库的任一操作失败,则参与此事务的所有数据库所做的所有操作都必须回滚。 一般情况下,某一数据库无法知道其它数据库在做什么,因此,在一个 DTP 环境中,交易中间件是必需的,由它通知和协调相关数据库的提交或回滚。而一个数据库只将其自己所做的操作(可恢复)影射到全局事务中。
XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数),交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。 XA 接口函数由数据库厂商提供。
二阶提交协议和三阶提交协议就是根据这一思想衍生出来的。可以说二阶段提交其实就是实现XA分布式事务的关键(确切地说:两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做)
二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。通常,二阶段提交也被称为是一种协议(Protocol))。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
所谓的两个阶段是指:第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。
默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。
《阿里巴巴Java开发手册》中建议设置HashMap的初始化容量。

那么,为什么要这么建议?
先来写一段代码在JDK 1.7 (jdk1.7.0_79)下面来分别测试下,在不指定初始化容量和指定初始化容量的情况下性能情况如何。
1 | public static void main(String[] args) { |
以上代码不难理解,创建了3个HashMap,分别使用默认的容量(16)、使用元素个数的一半(5千万)作为初始容量、使用元素个数(一亿)作为初始容量进行初始化。然后分别向其中put一亿个KV。
输出结果:
1 | 未初始化容量,耗时 : 14419 |
从结果中,可以知道,在已知HashMap中将要存放的KV个数的时候,设置一个合理的初始化容量可以有效的提高性能。
HashMap有扩容机制,就是当达到扩容条件时会进行扩容。HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。在HashMap中,threshold = loadFactor * capacity。
所以,如果没有设置初始容量大小,随着元素的不断增加,HashMap会发生多次扩容,而HashMap中的扩容机制决定了每次扩容都需要重建hash表,是非常影响性能的。
从上面的代码示例中,还可以发现,同样是设置初始化容量,设置的数值不同也会影响性能,那么当已知HashMap中即将存放的KV个数的时候,容量设置成多少为好呢?
本文在阅读大话数据结构这本书的基础上,结合java语言的特点,来理解排序。
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 简单选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 直接插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(nlogn)~O(n^2) | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(n^2) | O(logn)~O(n) | 不稳定 |
假设含有n个记录的序列为{r1,r2,……,rn},其相应的关键字分别为{k1,k2,……,kn},需确定1,2,……,n的一种排列p1,p2,……,pn,使其相应的关键字满足kp1≤kp2≤……≤kpn(非递减或非递增)关系,即使得序列成为一个按关键字有序的序列{rp1,rp2,……,rpn},这样的操作就称为排序。假设ki=kj(1≤i≤n,1≤j≤n,i≠j),且在排序前的序列中ri领先于rj(即i<j)。如果排序后ri仍领先于rj,则称所用的排序方法是稳定的;反之,若可能使得排序后的序列中rj领先ri,则称所用的排序方法是不稳定的。
内排序与外排序:根据在排序过程中待排序的记录是否全部被放置在内存中。内排序是在排序整个过程中,待排序的所有记录全部被放置在内存中。外排序是由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。
对于内排序来说,排序算法的性能主要是受三个方面影响:时间性能;辅助空间;算法的复杂性。
排序的结构图如下:
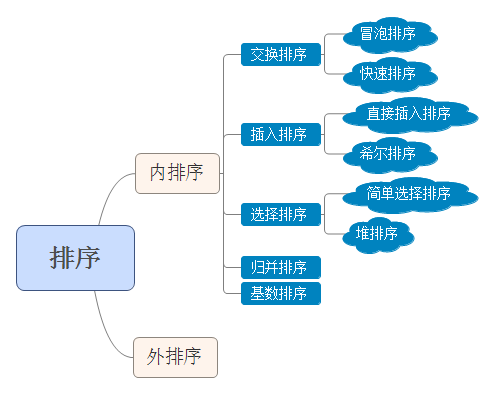
包含传统冒泡和优化冒泡两种方式实现
1 | public class Sort { |
包含递归和尾递归优化实现